
1. 키워드를 식별자로 사용하는 방법
<sql />
'keyword'
"keyword"
[keyword]
`keyword`
키워드를 테이블명이나 데이터베이스명 등에는 사용하는것을 가급적 피하고, 어떤 이유로 키워드를 식별자로 사용해야 하는 경우에는 위의 4가지 방법 중 하나를 사용한다.
따옴표(’)로 키워드를 둘러싸면 문자열 값으로 처리된다.
2. 주석 작성
SQL문에서 어떤 의견이나 설명을 남기고 싶은 경우 주석을 추가하려는 경우에는 두가지 방법이 있다.
<code />
-- 주석
/* 주석 */
주석이 작성되어도 SQL문을 실행할 때 무시되므로 실행 결과에 영향을 주지 않는다.
--주석 형식으로 주석을 작성한 경우 --부터 행 마지막까지 작성된 문자열은 주석이 된다.
/* 주석 */ 과 같은 형식으로 주석을 작성하면 /*에서 */까지 작성된 문자열은 주석이 된다.
3. 데이터베이스 백업
- 기존 db파일을 복사 - 다른 경로에 붙여넣기 하고 이름을 바꾸어 보관한다. db안에 기존 테이블은 그래도 남아 있다.
- .backup 명령과 .restore 명령을 사용하는 백업 및 복구도 명령어도 있다.
4. SQLite3에서 사용되는 데이터 타입
여러 데이터베이스에서는 컬럼별로 데이터 타입을 지정한다. 그로 인해 컬럼마다 저장할 수 있는 값이 정해진다. SQLite3는 테이블을 정의할 때 컬럼마다 데이터 타입을 지정할 필요는 없다.
단지 데이터 유형을 저장하지 않은 경우에도 컬럼에 저장된 값이 어떤 데이터 타입인지를 구분하고 NULL, INTEGER, REAL, TEXT, BLOB 이렇게 5가지 데이터 타입으로 분류된다.
| 데이터 타입 | 설명 |
| NULL | NULL 값 |
| INTEGER | 부호있는 정수. 1, 2, 3, 4, 6, or 8 바이트로 저장 |
| REAL | 부동 소수점 숫자. 8 바이트로 저장 |
| TEXT | 텍스트. UTF-8, UTF-16BE or UTF-16-LE 중 하나에 저장 |
| BLOB | Binary Large OBject. 입력 데이터를 그대로 저장 |
SQL문에 작성된 작성 방법에 따라 그 값의 데이터 유형이 결정된다. 작은 따옴표로 둘러싸여 있으면 TEXT타입으로, 소수점도 지수도 없으면 INT타입으로, 소수점 또는 지수가 있으면 REAL 타입으로 결정된다.
컬럼 데이터 타입을 지정된 경우에도 다른 데이터 타입의 값을 저장할 수 있는데, 컬럼의 데이터 타입과 값의 데이터 타입의 조합에 따라 값의 데이터 타입이 변환하여 저장한다.
- 변환은 다음과 같이 된다.
- TEXT 타입의 컬럼에 INTEGER 또는 REAL 데이터 타입의 값이 포함 된 경우, TEXT 타입으로 변환 되어 저장된다.
- NUMERIC 타입의 컬럼에 TEXT 타입의 값이 포함 된 경우, INTEGER 타입 또는 REAL 타입으로 변환을 해보고 성공하면 데이터 타입으로 저장되지만, 실패하면 TEXT 타입 그대로 저장된다.
- INTEGER 타입의 컬럼에 정수로 나타낼 수 있는 REAL 타입의 값(예 : 34.0 등), 또는 같은 타입의 TEXT 타입의 값이 포함된 경우 INTEGER 형으로 변환되어 저장된다.
- REAL 타입의 컬럼에 INTEGER 값이 포함 된 경우 REAL 타입으로 변환되어 저장한다.
- NONE 타입의 컬럼의 경우는 변환이 처리가 없다.
5. 컬럼에 데이터 타입을 지정하는 방법
데이터 타입이 문자열 int를 포함한 경우 integer 타입이 된다.
<code />
create table student(id int, name text); -- integer 대신에 int 작성
데이터 타입이 문자열 char, clob, text 중 하나를 포함하는 경우 text 타입이 된다.
<code />
create table teacher(id integer, name varchar); -- text 대신에 varchar로 작성
데이터 타입이 문자열 blob를 포함한 경우, 또한 데이터 타입이 지정되지 않은 경우는 NONE타입이 된다.
데이터 타입이 문자열 REAL, FLOA, BOUB중 하나를 포함하는 경우 REAL 타입이 된다.
위의 어디에도 포함되지 않은 경우는 NUMBERIC 타입이 된다.
6. 문자열 이스케이프 처리
SQLite에서 테이블에 문자열 값을 저장할 때는 작은 따옴표(’)로 묶어서 작성하지만, 문자열에 따옴표가 있는 경우에는 이스케이프 처리가 필요하다.
작은 따옴표(’)를 포함시킨 문자열을 작성하려면 ‘’ 처럼 이어서 작성하면 된다.
<code />
insert into test values('I''m a student');
7. 테이블(Table) - 테이블 스키마(구조) 확인
데이터베이스에 생성되는 테이블이 어떤 create 문을 사용되어 만들어졌는지 확인하는 방법이다.
첫 번째 방법
sqlite_master 테이블에서 조회
<code />
select * from sqlite_master;

위와 같이 데이터를 조회할 수 있다.
현재 3개의 테이블이 생성되어 있기에 sqlite_master 테이블에는 6개의 행(row)이 표시되고 있다. 각각 행에 name 컬럼은 테이블명, sql 컬럼에는 테이블이 작성되었을 때의 CREATE TABLE문이 표시되고 있다. 이렇게 sqlite_master테이블을 조회하여 테이블이 어떻게 생성되었는지 확인할 수 있다.
두번째 방법: 특정 테이블의 CREATE TABLE문을 확인하고 싶을 때 사용하는 방법이다.
<code />
SELECT * FROM sqlite_master where type = 'table' and name = 'ORDERS';

저장된 테이블명에 대한 데이터만 조회되었다.
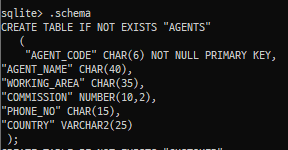
.schema 명령을 사용하여 조회
테이블의 스키마에 대한 정보조회만 하고자 한다면 SQLite 명령 .schema로도 확인할 수 있다.
<code />
.schema --스키마에 대한 정보조회만 함
8. 테이블 DEFAULT 제약 조건
테이블에 데이터를 추가할 때, 값을 생략한 컬럼은 보통 NULL이 저장되지만 NULL 대신에 기본으로 저장되는 값을 설정할 경우에는 DEFAULT 제약 조건으로 설정한다.
DEFAULT 제약 조건이란?
컬럼에 DEFAULT 제약 조건을 설정하면, 데이터를 추가할 때 값을 생략할 시에 기본값을 설정할 수 있다. DEFAULT 제약 조건을 컬럼에 설정하는 경우 형식은 다음과 같다.
<code />
CREATE TABLE 테이블명 (컬럼명 DEFAULT 값, ...);
기본값은 NULL, 숫자, 문자열을 지정할 수 있다.
예시
<code />
/*테이블 생성(id, name, price)*/
create table product(id int, name text default 'no name', price integer default 0);
insert into product values (1, 'pc', 75000), (4, 'desk', 18000); -- 값 삽입
insert into product (id, price) -- id와 price만 값 삽입
values (6, 18000);
sqlite> select * from product; -- 데이터 확인
┌────┬─────────┬───────┐
│ id │ name │ price │
├────┼─────────┼───────┤
│ 1 │ pc │ 75000 │
│ 4 │ desk │ 18000 │
│ 6 │ no name │ 18000 │ -- no name으로 기본값이 삽입된것을 확인할 수 있다.
└────┴─────────┴───────┘
데이터를 추가한 날짜를 기본값으로 설정
DEFAULT 제약 조건에 지정된 기본 값으로 다음 값을 지정하면 데이터를 추가했을 때 그 당시의 날짜와 시간을 가져 디폴트 값으로 컬럼할 수 있다. (시간대는 UTC이다.)
지정값 형식
| CURRENT_TIME | HH : MM : SS |
| CURRENT_DATE | YYYY-MM-DD |
| CURRENT_TIMESTAMP | YYYY-MM-DD HH : MM : SS |
<code />
CREATE TABLE user (id int, name text, date_time default CURRENT_TIMESTAMP); -- 테이블 생성
insert into user(id, name) values (1, 'julia'), (2, 'minho'); -- 값 추가
select * from user; -- 조회
┌────┬───────┬─────────────────────┐
│ id │ name │ date_time │
├────┼───────┼─────────────────────┤
│ 1 │ julia │ 2023-05-31 10:53:07 │ -- 기본값으로 default값인 현재 날짜 추가됨
│ 2 │ minho │ 2023-05-31 10:53:07 │ -- UTC 기준의 날짜이다.
└────┴───────┴─────────────────────┘
** 만약 한국 시간대로 출력되게 하고 싶다면?(--> 더 찾아볼 것) **
9. 인덱스(index)
의미
인덱스는 테이블의 정보를 검색했을 때 검색의 대상으로 자주 사용하는 컬럼의 값만 쉽게 찾을 수 있도록 해 놓은 것이다.
인덱스란?
: 인덱스는 테이블의 정보를 검색했을 때 검색의 대상으로 자주 사용하는 컬럼의 값만 꺼내 쉽게 찾을 수 있도록 해 놓은 것이다.
예시
<code />
sqlite> select * from agents;
┌────────────┬────────────┬──────────────┬────────────┬──────────────┬─────────┐
│ AGENT_CODE │ AGENT_NAME │ WORKING_AREA │ COMMISSION │ PHONE_NO │ COUNTRY │
├────────────┼────────────┼──────────────┼────────────┼──────────────┼─────────┤
│ A007 │ Ramasundar │ Bangalore │ 0.15 │ 077-25814763 │ │
│ A003 │ Alex │ London │ 0.13 │ 075-12458969 │ │
│ A008 │ Alford │ New York │ 0.12 │ 044-25874365 │ │
│ A011 │ Ravi Kumar │ Bangalore │ 0.15 │ 077-45625874 │ │
│ A010 │ Santakumar │ Chennai │ 0.14 │ 007-22388644 │ │
│ A012 │ Lucida │ San Jose │ 0.12 │ 044-52981425 │ │
│ A005 │ Anderson │ Brisban │ 0.13 │ 045-21447739 │ │
│ A001 │ Subbarao │ Bangalore │ 0.14 │ 077-12346674 │ │
│ A002 │ Mukesh │ Mumbai │ 0.11 │ 029-12358964 │ │
│ A006 │ McDen │ London │ 0.15 │ 078-22255588 │ │
│ A004 │ Ivan │ Torento │ 0.15 │ 008-22544166 │ │
│ A009 │ Benjamin │ Hampshair │ 0.11 │ 008-22536178 │ │
└────────────┴────────────┴──────────────┴────────────┴──────────────┴─────────┘
agent_name 컬럼의 값을 검색하려고 할 때, 테이블의 저장되는 데이터는 차례로 나열되어 있는 것이 아니므로 원하는 데이터가 있는지 차례로 검색해 나갈 것이다. 데이터가 작으면 문제가 없지만, 수백만개의 데이터가 저장되어 있는 경우 위에서부터 찾아가는 것은 매우 비효율적이다.예를 들어 agent_name 컬럼의 값을 대상으로 한 인덱스를 만든다면 다음과 같은 것이다.
이러한 경우 인덱스를 생성하면 검색 속도를 향상시킬 수 있다. 인덱스를 간단히 대상 컬럼의 데이터로 검색하여, 빠르게 검색할 수 있도록 가공하여 저장해 둔 것이다.
예를 들어 agent_name 컬럼의 값을 대상으로 한 인덱스를 만든다면 다음과 같은 것이다.
<sql />
sqlite> select agent_code, agent_name from agents order by 2;
┌────────────┬────────────┐
│ AGENT_CODE │ AGENT_NAME │
├────────────┼────────────┤
│ A003 │ Alex │
│ A008 │ Alford │
│ A005 │ Anderson │
│ A009 │ Benjamin │
│ A004 │ Ivan │
│ A012 │ Lucida │
│ A006 │ McDen │
│ A002 │ Mukesh │
│ A007 │ Ramasundar │
│ A011 │ Ravi Kumar │
│ A010 │ Santakumar │
│ A001 │ Subbarao │
└────────────┴────────────┘
인덱스의 장단점
인덱스를 생성 해두면 유용하지만, 테이블과는 별도로 데이터를 독자적으로 보유하고 있기 때문에 테이블에 데이터를 추가하면 인덱스로도 데이터가 추가된다. 또한 데이터를 추가할 때마다 정렬도 다시 이루어진다. 결과적으로 → 처리 속도가 느려진다.
UNIQUE 인덱스 생성
인덱스의 대상이 되는 테이블의 컬럼에 저장되는 값은 중복된 값이 포함되어 있어도 상관 없지만, 중복 값을 허용하지 않도록 설정할 수 있다. 이러한 인덱스를 유니크(Unique)인덱스라고 한다.
<code />
CREATE UNIQUE INDEX 인덱스명 ON 테이블명 (컬럼명1, 컬럼명2, ...);
대상이 되는 컬럼에 중복된 값이 포함되어 있으면 유니크 인덱스는 만들 수 없다.
또한 유니크 인덱스를 생성한 후에 유니크 인덱스의 대상인 컬럼에 이미 저장되어 있는 값과 동일한 데이터는 테이블에 추가할 수 없다.
여러 컬럼의 조합하여 인덱스를 작성하는 경우에는 각각의 컬럼에서 중복된 값이 포함되어 있어도 지정된 모든 컬럼 값의 조합이 중복되지 않으면 유니크 인덱스를 만들 수 없다.
<code />
sqlite> select * from user;
┌──────────┬─────┬─────────┐
│ name │ old │ address │
├──────────┼─────┼─────────┤
│ mingyu │ 27 │ seoul │
│ seungwan │ 26 │ jeju │
│ myeongho │ 27 │ china │
│ dogyeom │ 26 │ seoul │
│ joshua │ 28 │ america │
└──────────┴─────┴─────────┘
값들을 추가해서 정리해 보았다.
여기서 생성한 테이블에 name 컬럼을 대상으로 유니크 인덱스를 만들어 보자. name 컬럼에는 현재 중복된 값이 포함되어 있지 않으므로 name 컬럼을 대상으로 한 유니크 인덱스를 만들 수 있다.
<code />
sqlite> create unique index nameindex on user (name);
유니크 인덱스가 생성되었다.
생성된 유니크 인덱스의 대상이 되는 컬럼에는 이미 저장되어 있는 것과 같은 값을 가지는 데이터를 추가할 수 없다. 예를 들어, 같은 이름을 가진 데이터를 추가하려고 하면 UNIQUE constraint failed: user.name (19) 오류가 발생한다.
<code />
sqlite> insert into user values ('mingyu', 26, 'seoul');
Runtime error: UNIQUE constraint failed: user.name (19)

또한 이미 중복된 데이터가 있는 열에 유니크 인덱스를 생성하려고 하면 오류가 발생한다.
PRIMARY KEY 제약 조건은 테이블에 하나 밖에 설정할 수 없는 반면, UNIQUE 제약 조건과 UNIQUE 인덱스는 같은 테이블에 여러 설정하거나 생성할 수 있다.
인덱스 삭제
생성된 인덱스를 삭제하려면 DROP INDEX 문을 사용한다. 형식은 다음과 같다.
<code />
DROP INDEX 인덱스명;
삭제하기 전에 SQLite 명령 .indices를 사용하여 생성된 인덱스를 확인한다.
'개발공부 > SQL & DB' 카테고리의 다른 글
| [SQL] CSV 파일 SQLite 이용해 DB파일로 바꾸기 (0) | 2023.06.03 |
|---|---|
| [SQL] 4가지 모드(box, column, table, markdown) (0) | 2023.06.01 |
| [SQL] 캐글 데이터 활용/타이타닉 호 데이터 분석 (0) | 2023.05.30 |
| [SQL] 명령어 공부하기_INSERT, DELETE, UPDATE, SELECT (0) | 2023.05.29 |
| [SQL] SQLite3 다운로드 및 실행하기, 값추가 및 조회 (0) | 2023.05.29 |
