학습 내용 출처: 유데미 안젤라 파이썬 강의
배울 내용
- 판다스 데이터프레임에 파이썬 목록 슬라이싱 기술 적용
- .agg() 함수를 사용하여 데이터를 집계하는 법
- 맷플롯립에서 두 개의 축이 있는 산점도, 막대 차트, 꺾은선형 차트를 만드는 법
- 기본키와 외래키로 구성된 데이터베이스 스키마를 이해
- 공통의 키를 공유하는 데이터프레임을 병합하는 법
1. 개발환경
- 운영체제: Window OS, Window 10
- 개발언어: Python 3.11
- 개발 툴: Google Colab
- 추가 패키지: Matplotlib, pandas
2. 사용 자료
3. 데이터 분석
구글 콜랩에서 이미지 추가하는 방법
<python />
<img src="https://i.imgur.com/49FNOHj.jpg">
주피터에서 추가하는 방법
폴더에 있는 파일을 불러오면
<python />
<img src="assets/bricks.jpg">
판다스 가져오기
<python />
import pandas as pd
matplotlib 글씨체 한국어 적용(나눔고딕 폰트)
<python />!sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf
3.1. 구조 확인하기
3.2. colors.csv
.csv 파일을 읽고 첫 번째 5 행을 살펴보자.
<python />
colors = pd.read_csv('./data/colors.csv')
colors.head()

색상 이름과 해당 RGB 값이 있는 다섯 열이 있음을 알 수 있다. 고유한 색상의 수를 찾으려면 name 열의 모든 항목이 고유한지 여부를 확인하기만 하면 된다.
<python />
colors['name'].nunique()
출력
135
→ 레고 블럭에 135개의 고유한 색상이 있다는 것이 나타난다.
투명한 색상의 갯수 구하기
,groupby() 메소드와 .count() 메소드를 결합한다.
<python />
colors.groupby('is_trans').count()
또는 value_count()를 사용한다.
<python />colors.is_trans.value_counts()
동일한 결과가 나온다.
3.3. sets.csv
sets.csv에 레고 세트 목록이 있다. 데이터에는 각 세트가 몇 년에 출시되었는지와 세트당 부품 수가 나온다.
데이터 불러오기
<python />
sets = pd.read_csv('./data/sets.csv')
sets.head()
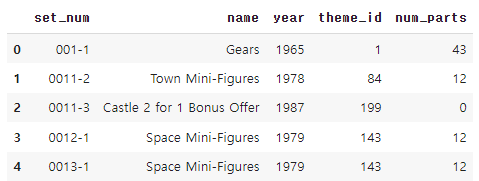
연도별 출시된 레고 세트 출력해보기
- .sort_values() 메소드를 사용하여 오름차순으로 정렬한다.
- .head() 메서드를 사용하여 상위 5개의 행을 출력한다.
<python />
sets.sort_values('year').head()

→ 레고는 1949년부터 시작되었음을 알 수 있다! 세트의 이름은 볼 게 없지만 출시 첫 해 회사가 몇 가지 제품을 판매했는지 알아보자.
연도 열의 값이 1949인 행을 검색해 보자.
<python />
sets[sets['year'] == 1949]
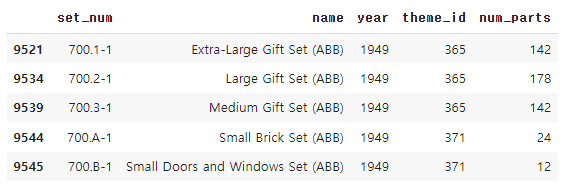
1949년에 레고는 다섯 가지 세트만 가지고 판매를 시작했다.( 조건에 따라 데이터프레임을 필터링)
이제 가장 많은 부품을 가진 레고 세트를 알아보자. 최다 부품을 찾으려면 num_parts 열을 기준으로 정렬할 때 asending 인수를 False로 설정해야 한다.
<python />
sets.sort_values('num_parts', ascending=False).head()

→ 지금까지 생산된 것 중 가장 큰 레고 세트는 약 10,000개 부품이였다.

구글링해보니 바로 이 제품이다. 보기만 해도 뭐가 많아보이긴 한다 ㅋㅋ
3.4. 시간 변화에 따른 출시 세트 수 시각화
이제 레고 회사가 매해 전년 대비 얼마나 많은 세트를 더 출시해 왔는지 살펴보자.
시간이 지남에 따라 레고의 제품 공급이 어떻게 변했는지 알 수 있다.
matplotlib import 그리고 글씨체 설정
<python />
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] =False
연도를 인덱스로, 세트 수를 그 값으로 하는 시리즈를 생성한다.
<python />
sets_by_year = sets.groupby('year').count()
sets_by_year['set_num'].head

→ 이를 통해 레고가 운영 초반 몇 년 동안은 10가지 미만의 서로 다른 세트를 출시해왔다는 점을 알 수 있다. 하지만 2019년부터는 회사가 성장하여 한 해에 840세트를 출시한 모습을 볼 수 있다.
2021년 항목도 있지만, csv파일은 2020년도 후반부터이므로, 이 데이터를 지우고 그래프로 나타내야 한다.
<python />sets_by_year.head()
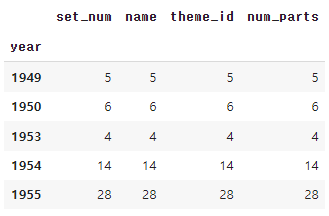
연도별 레고 세트 수를 합산한 후, 이 데이터를 matplotlib에서 꺾은선 차트를 이용해 시각화해 보자.
하지만 csv 파일에 데이터가 2020년 후반부터 잇으므로 차트에서 최근 2년치 데이터를 없애(슬라이싱하여) 표현해 보겠다.
<python />
plt.plot(sets_by_year.index[:-2], sets_by_year.set_num[:-2])

→ 레고는 처음 45여 년간 제공하는 데이터를 꾸준히 증가시켰지만 실제로 회사에서 생산한 세트 수가 급격히 증가한 것은 1990년대 중반이었다. 또한 차트에서 2000년대 초반에 잠시 하락했고, 2005년경 강한 회복을 보여준 것 역시 확인할 수 있다.
4. 판다스 .agg() 함수 사용
데이터를 요약해야 하는 경우가 종종 있습니다. 이 경우 .groupby() 함수가 굉장히 유용하다. 그러나 특정 데이터프레임 열에 기반하여 더 많은 작업을 실행하고자 할 때 사용하는 게 .agg() 메소드이다.
모든 달이 들어간 연도를 가지고 연도별 테마의 수를 계산하려고 한다. 때문에 연도별로 데이터를 그룹화한 다음, 해당 연도 고유 theme_ids의 수를 계산해야 합니다.
판다스 .agg()함수는 aggregate의 출임말로, 데이터의 집계를 수행하는 데 사용된다. DataFrame과 Series 모두에서 사용할 수 있다.
.agg() 함수의 주요 사용 사례와 특징은 다음과 같다.
1. 다양한 집계 연산 적용: DataFrame의 여러 열에 서로 다른 집계 연산을 동시에 적용할 수 있다.
<python />
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
df.agg({
'A': 'sum',
'B': 'mean',
'C': 'max'
})

2. 여러 집계 연산 동시 적용: 한 열에 여러 집계 연산을 동시에 적용할 수 있다.
<python />
df.agg({
'A': ['sum', 'mean'],
'B': ['min', 'max']
})
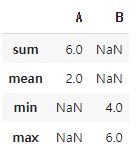
3. 커스텀 집계 함수 사용: 람다 함수나 사용자 정의 함수를 사용하여 집계를 수행할 수 있다.
<python />
df['A'].agg(lambda x: (x**2).sum())

4. Series에 적용: Series에 .agg() 함수를 사용하여 여러 집계 연산을 한 번에 적용할 수 있다.
<python />
df['A'].agg(['sum', 'mean', 'min'])

여기서 마지막 4. Series에 적용을 .groupby와 응용하여 사용해 보자.
연도별 테마 수
<python />
# 모든 달이 들어간 연도를 가지고 연도별 테마의 수를 계산하려고 함.
# 연도별로 데이터를 그룹화한 후, 해당 연도 고유 theme_ids 수를 계산해야 함
themes_by_year = sets.groupby('year').agg({'theme_id': pd.Series.nunique})
# 기억할 것은, agg() 메서드가 인자에서 딕셔너리 역할을 수행한다는 점이다.
# 이 딕셔너리에서 각 열에 어떤 작업을 할 지 구체화하게 됨.
<python />
themes_by_year.rename(columns = {'theme_id':'nr_themes'}, inplace=True)
themes_by_year.head()
theme_id 열에 적절한 이름으로 수정해준다.

이를 시각화해보자.
<python />
plt.plot(themes_by_year.index[:-2], themes_by_year.nr_themes[:-2])
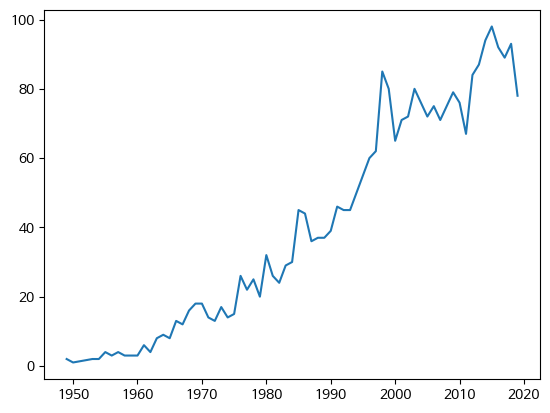
→ 차트에서 레고가 1990년대 중반까지 꽤 일관되게 점점 더 많은 테마를 추가했음을 알 수 있다. 이후 2010년대 초반까지 약 10년 동안 테마의 수는 정체되었다.
축이 다른 선형 차트를 중첩하기
<python />
ax1 = plt.gca() # 현재 축 개체를 가져옴
ax2 = ax1.twinx() # 또다른 축 개체 ax2를 생성해줌
# 스타일 추가
ax1.plot(sets_by_year.index[:-2], sets_by_year.set_num[:-2], color='g')
ax2.plot(themes_by_year.index[:-2], themes_by_year.nr_themes[:-2], 'b')
ax1.set_xlabel('Year')
ax1.set_ylabel('세트의 수', color='green')
ax2.set_ylabel('테마의 수', color='blue')
<python />
ax1 = plt.gca() # 현재 축 개체 가져오기
ax2 = ax1.twinx()
동일한 차트에 두 개의 개별 축을 세워 데이터를 구성하고 표시할 수 있도록 해야 한다. -> 이를 위해 맷플로립에서 축 개체를 가져와야 한다. 이 부분이 ax1 = plt.gca() 부분이다.
그 다음 또다른 축 개체 ax2를 생성해준다. 핵심이 되는 것은 .twinx() 메서드를 사용하여 ax1과 ax2가 동일한 x축을 사용하도록 하는 것이다.

4.1. 산점도: 레고 세트 당 평균 부품 수
시간 흐름에 따른 복잡도를 산점도로 나타내 보자.
<python />
parts_per_set = sets.groupby('year').agg({'num_parts': pd.Series.mean})
parts_per_set.head()
이번에는 .agg() 함수에 딕셔너리를 적용하여 mean() 함수를 써서 num_parts 열을 작업해 본다.
이 방식으로 데이터를 연도별로 그룹화한 다음 해당 연도의 평균 부품 수를 계산한다.
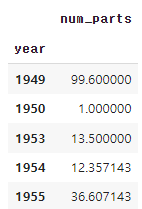
<python />
plt.scatter(parts_per_set.index[:-2], parts_per_set.num_parts[:-2])

→ 차트에서 평균 부품 수를 기준으로 레고 세트의 크기와 복잡도가 증가하는 흐름을 확실히 파악할 수 있다. 2010년대에는 평균 세트에 약 200개의 개별 부품이 들어 있었는데, 이는 대략 1960년대 레고 세트에 들어 있던 것의 두 배이다.
4.2. 연관 데이터베이스 스키마: 기본키와 외래키
레고 테마당 세트의 수
테마 당 세트의 수를 계산하기 위해 theme_id 열에 .value_counts() 메소드를 사용하면 된다. 문제는 테마의 실제 이름을 알 수 없기 때문에, themes.csv에서 theme_id에 기초한 테마의 이름을 찾아본다.
연관 상태

theme_id는 sets.csv 안에서 외래키이다. 서로 다른 세트가 같은 테마의 일부를 이룰 수 있다. 그러나 themes.csv 안에 각각의 theme_id가 id로 불리고 있는데 이것은 고유한 것이다. 이 고유성으로 인해 id 열이 themes.csv 안에서 기본키가 된다.
4.3. themes.csv
<python />
themes = pd.read_csv('data/themes.csv')
themes.head()
테마의 이름이 스타워즈인것만 검색한다.
<python />
themes[themes.name == 'Star Wars']

sets.csv에서 어떤 제품이 이 테마에 해당하는지 확인할 수 있다.
<python />
sets[sets.theme_id == 18]

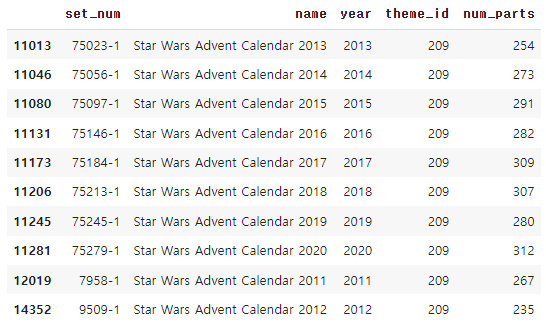
<python />
sets[sets.theme_id == 209]
4.4. 데이터 병합하기
.merge() 메서드를 사용해 별개의 두 데이터프레임을 하나로 결합해 보자.
머지 메서드는 양쪽의 데이터프레임에서 같은 이름을 가진 열에 적용된다.
<python />
set_theme_count = sets['theme_id'].value_counts()
# set_theme_count[:5]
set_theme_count

id 라는 이름의 열이 있다는 것을 확인하기 위해 판다스 시리즈를 판다스 데이터프레임으로 변환한다.
<python />
set_theme_count = pd.DataFrame({'id': set_theme_count.index,
'set_count': set_theme_count.values})
set_theme_count.head()

딕셔너리의 키가 열 이름이 된다.
두 개의 데이터프레임을 하나의 특정 열에 .merge()하기 위해서는 그 두 데이터프레임 및 병합할 열 이름을 알려줘야 한다. 그래서 on='id'을 설정하는 것이다. set_theme_count와 themes 데이터프레임 둘 다 이 이름이 있는 열이 있다.
<python />
merged_df = pd.merge(set_theme_count, themes, on='id')
merged_df[:3]

막대그래프로 나타낸다
<python />
plt.figure(figsize=(14, 8))
plt.xticks(fontsize=14, rotation=45)
plt.yticks(fontsize=14)
plt.ylabel('세트의 수', fontsize=14)
plt.xlabel('테마의 이름', fontsize=14)
plt.bar(merged_df.name[:10], merged_df.set_count[:10], color='lightblue')

-> 스타워즈는 가장 많은 레고 세트를 낸 테마라는 것을 알 수 있다.
