1. 자료
<python />
# 도미 생선의 길이
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
# 도미생선의 무게
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
# 빙어 생선의 길이와 무게
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
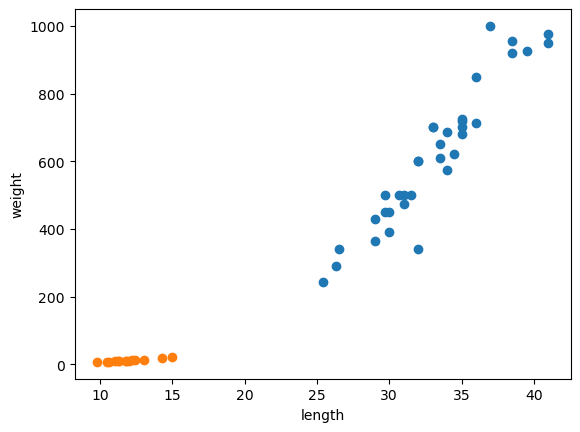
2. 분포도 시각화하기
<python />
# 맷플로립 라이브러리 임포트
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight) # 도미의 산점도
plt.scatter(smelt_length, smelt_weight) # 빙어의 산점도
plt.xlabel('length') # x축은 길이
plt.ylabel('weight') # y축은 무게
plt.show() # 선형적: 일직선에 가까운 형태로 나타남

3. 리스트 세로 방향으로 만들기
(리스트 안에 리스트들이 들어있는 2차원 형태)
<python />
# 사이킷런 패키지를 사용하려면 리스트를 세로 방향으로 늘어트린 2차원 리스트를 만들어야 함
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
fish_data = [[l, w] for l, w in zip(length, weight)]
fish_data
출력결과
4. 정답지 만들기
<python />
# 도미를 1, 빙어를 0으로 나타내 정답지를 만들어 보자.
fish_target = [1] * 35 + [0] * 14
fish_target
출력결과: 도미는 1, 빙어는 0
더보기
<python />
[1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0]
5. KNeighborsClassifier 알고리즘 임포트하기
<python />
# 사이킷런에서 k -최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트한다.
from sklearn.neighbors import KNeighborsClassifier
# 임포트한 클래스의 객체를 생성한다.
kn = KNeighborsClassifier()
# 이 객체에 fish_data와 fish_target을 사용해서 도미를 참기 위한 기준을 학습시킨다.
# 이런 과정을 머신러닝에서는 "훈련"이라고 부른다.
# 사이킷런에서는 fit()메서드가 이런 역할을 한다.
# 이 메서드에 fish_data와 fish_target을 순서대로 전달해 보자.
kn.fit(fish_data, fish_target) # fit 메서드는 주어진 데이터로 알고리즘을 훈련시킨 뒤 훈련한다.
# 이런 객체(모델)이 얼마나 잘 훈련되어 있는지 평가해 보자.
# 사이킷런에서 모델을 평가하는 메서드는 score() 메서드이다. 이 메서드는 0과 1사이의 값을 반환한다.
# 1은 모든 데이터의 값을 정확하게 맞췄다는 것을 의미한다.
kn.score(fish_data, fish_target) # 1
값이 1이 나왔다. = 모든 fish_data의 값을 정확히 맞춘것이다. 이 값을 '정확도' 라고 부른다.
이 모델은 정확도가 100%이며 도미와 빙어를 정확하게 분류했다.
k-최근접 이웃 알고리즘은 어떤 데이터에 대한 값을 구할 때,
주위의 데이터를 보고 다수를 차지하는 것을 정답으로 평가한다.
6. predict() 메서드
<python />
kn.predict([[30, 600]])
predict() 메서드는 새로운 데이터의 정답을 예측한다.
이 메서드도 앞서 fit() 메서드와 마찬가지로 리스트의 리스트를 전달해야 한다. 그래서 임의의 값을 []로 두번 감싼다.
반환되는 값은 1이다. 우리는 앞서 도미를 1로 가정했기 때문에, 예측한 값은 도미이다.
출력결과
<python />
array([1])
k-최근접 이웃 알고리즘을 위해 준비해야 할 일은 데이터를 모두 가지고 있는 게 전부이다.
새로운 데이터에 대해 예측할 때는 가장 가까운 직선거리에 어떤 데이터가 있는지 살피기만 하면 된다.
단점은 이런 특징 때문에 데이터가 아주 많은 경우 사용하기 어렵다. 데이터가 크기 때문에 메모리가 많이 필요하고
직선거리를 예측하는데도 많은 시간이 필요하다.
<python />
kn._fit_X # _fit_X에 fish_data 저장
kn._y # _y에 fish_target 저장
<python />
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0])
출력결과
<code />
0.7142857142857143
아래와 동일한 값이 출력된다.
<python />
print(35/49)
'개발공부 > 머신러닝,딥러닝' 카테고리의 다른 글
| mediapipe 사용하여 팔굽히기 모션 인식하기 (0) | 2023.09.08 |
|---|---|
| CNN keras 모듈 사용하여 졸음 방지 모델 생성하기 (0) | 2023.09.05 |
| [Python] 로지스틱 회귀(LogisticRegression) 이용하여 붓꽃 데이터 분석 (0) | 2023.08.18 |
| [Python] 선형 회귀(Linear Regression) 이용하여 보스턴 하우스 집값 예측하기 (0) | 2023.08.17 |
