개발 환경 정리
운영체제: Windows OS
프로그래밍 언어: Python
개발 툴: Jupyter Lab
데이터 시각화: matplotlib, seaborn
데이터 처리: pandas, numpy
머신러닝 프레임워크: scikit-learn
필요한 모듈 / 라이브러리 import
# 라이브러리 import
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 가져오기
df = pd.read_csv('../data/iris/iris.csv')
df.head()
| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
데이터 확인
# 데이터 수치 확인
df.describe()
| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | |
|---|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 75.500000 | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 43.445368 | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 1.000000 | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 38.250000 | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 75.500000 | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 112.750000 | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 150.000000 | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
# 데이터 정보 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 150 non-null int64
1 SepalLengthCm 150 non-null float64
2 SepalWidthCm 150 non-null float64
3 PetalLengthCm 150 non-null float64
4 PetalWidthCm 150 non-null float64
5 Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
# 데이터 쉐입 확인
df.shape
(150, 6)# 데이터 컬럼 확인
df.columns
Index(['Id', 'SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm',
'Species'],
dtype='object')df.drop("Id", axis=1, inplace=True)
# id열은 상관관계에 필요가 없으므로 삭제함
# inplace=True는 원본 데이터에 영향을 미친다는 것을 의미함
df.head()
| SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
데이터 시각화하기
# 데이터 시각화하기
print(df['Species'].value_counts())
sns.countplot(x='Species', data=df)
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: Species, dtype: int64
<Axes: xlabel='Species', ylabel='count'>
plt.figure(figsize=(8, 4))
# sns.heatmap(df.corr(), annot=True, fmt='.0%')
sns.heatmap(df.corr(numeric_only=True), annot=True, fmt='.0%')
plt.show()
여기서 만난 경고창
경고 메세지 출력:
FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated.
In a future version, it will default to False.
Select only valid columns or specify the value of numeric_only to silence this warning.
sns.heatmap(df.corr(), annot=True, fmt='.0%')
경고 메시지를 읽어보면 DataFrame.corr() 메소드의 numeric_only 매개변수의 기본값이 미래의 버전에서 변경될 예정이라고 알려줍니다.
numeric_only 매개변수는 연산을 수치 데이터에만 적용할지 여부를 결정하는데 사용됩니다.
경고 메시지를 해결하려면 numeric_only 매개변수의 값을 명시적으로 지정해주면 됩니다.
예를 들어, 수치 데이터에만 연산을 적용하려면 numeric_only=True를 지정하면 됩니다
꽃받침의 너비와 길이는 상관관계가 없습니다.
꽃잎의 너비와 길이는 매우 높은 상관관계를 가지고 있습니다.
우리는 모든 특징들을 사용하여 알고리즘을 훈련시키고 정확도를 확인할 것입니다.
그 다음, 상관관계가 없는 2개의 특징만을 사용하여 알고리즘의 정확도를 확인하기 위해 1개의 꽃잎 특징과 1개의 꽃받침 특징을 사용할 것입니다.
따라서 데이터셋에 변동성이 있을 수 있어 정확도가 더 나아질 수 있습니다.
나중에 이를 확인해볼 것입니다.

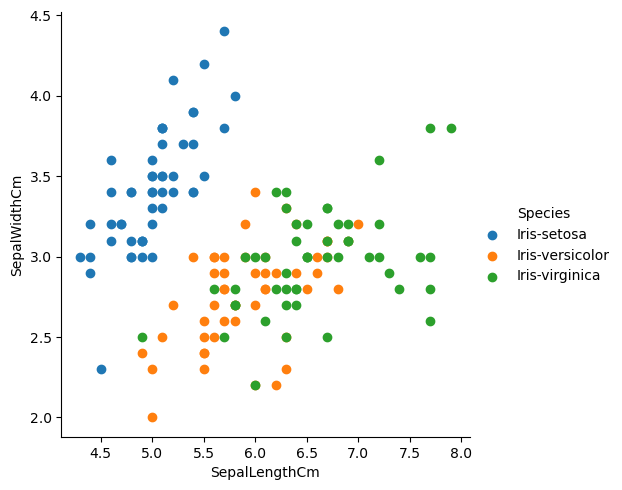
# seaborn의 패싯그리드로 다중 플롯 을 그려보자.
sns.FacetGrid(df, hue='Species', height=5).map(plt.scatter, 'SepalLengthCm', 'SepalWidthCm').add_legend()
<seaborn.axisgrid.FacetGrid at 0x1f81cd829b0>

# 페어플롯으로 종을 기준으로 나눠서 적용해보기
sns.pairplot(df.iloc[:,:], hue='Species')
<seaborn.axisgrid.PairGrid at 0x1f81ceb3970>
# 박스플롯을 종을 기준으로 적용해보기
df.boxplot(by='Species', figsize=(15, 15))
array([[<Axes: title={'center': 'PetalLengthCm'}, xlabel='[Species]'>,
<Axes: title={'center': 'PetalWidthCm'}, xlabel='[Species]'>],
[<Axes: title={'center': 'SepalLengthCm'}, xlabel='[Species]'>,
<Axes: title={'center': 'SepalWidthCm'}, xlabel='[Species]'>]],
dtype=object)
알고리즘 적용해보기(로지스틱 회귀 모델)
1. 훈련 데이터와 테스트 데이터로 나눈다. 테스트 데이터셋은 일반적으로 훈련 데이터보다 작다 - 훈련을 보다 잘 시킬 수 있도록
2. 적합한 알고리즘을 선택한다. (분석 혹은 회귀)
3. 훈련 데이터를 알고리즘에 적용하여 훈련시킨다. .fit() 메서드를 사용한다.
4. 결과를 예측하기 위해 훈련시킨 알고리즘에 테스트 데이터를 예측한다. .predict() 메서드를 사용한다.
5. 예측한 결과와 실제 결과를 비교하여 정확도를 확인한다.
# 로지스틱 회귀 모델 import하기
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
# 데이터 분류하기
X = df.iloc[:, 0:4]
Y = df['Species']
X.head()| SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, random_state=0)
print("훈련한 쉐입", X_train.shape)
print("테스트 쉐입", X_test.shape)
훈련한 쉐입 (112, 4)
테스트 쉐입 (38, 4)
log = LogisticRegression()
log.fit(X_train, Y_train)
# print(log.fit(X_train, Y_train))
pred = log.predict(X_test)
print('>> score 결과: ', log.score(X_train, Y_train))
print('>> accuracy_score 결과: ', metrics.accuracy_score(pred,Y_test))
>> score 결과: 0.9821428571428571
>> accuracy_score 결과: 0.9736842105263158
# 어떤것이 다른지 확인해보기
test_list = log.predict(X_test).tolist()
pred_list = Y_test.to_list()
for i, j in zip(test_list, pred_list):
if i==j:
print('>> 일치', end=' |')
else:
print('>> 불일치', end='|')
print('실제 데이터: ', i, '\t', '예측한 데이터: ', j)
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-virginica 예측한 데이터: Iris-virginica
>> 일치 |실제 데이터: Iris-versicolor 예측한 데이터: Iris-versicolor
>> 일치 |실제 데이터: Iris-setosa 예측한 데이터: Iris-setosa
>> 불일치|실제 데이터: Iris-virginica 예측한 데이터: Iris-versicolor
정확도는 98프로가 나왔고, 1개의 데이터가 틀렸다.
https://github.com/guaba98/machine_learning_study
GitHub - guaba98/machine_learning_study: 머신러닝/딥러닝 공부 기록
머신러닝/딥러닝 공부 기록. Contribute to guaba98/machine_learning_study development by creating an account on GitHub.
github.com
'개발공부 > 머신러닝,딥러닝' 카테고리의 다른 글
| mediapipe 사용하여 팔굽히기 모션 인식하기 (0) | 2023.09.08 |
|---|---|
| CNN keras 모듈 사용하여 졸음 방지 모델 생성하기 (0) | 2023.09.05 |
| [Python] 선형 회귀(Linear Regression) 이용하여 보스턴 하우스 집값 예측하기 (0) | 2023.08.17 |
| [Python] sklearn 모듈 KNeighborsClassifier 알고리즘으로 도미, 빙어 구분하기 (0) | 2023.08.16 |
