공부에 참고한 링크
개발환경
- 운영체제: Window 10 64 bit
- 개발언어: Python 3.11
- 개발 툴: Jupyter Lab
- 추가 패키지: mediapipe, opencv-python
라이브러리 & 모듈 설치
MediaPipe, opencv-python 설치
!pip install mediapipe opencv-pythonMediaPipe란?
MediaPipe는 Google에서 개발한 오픈 소스 플랫폼 프레임워크로, 개발자들이 머신러닝을 기반으로 한 모바일 및 웹 애플리케이션에서 사용할 수 있는 다양한 미리 만들아진 솔루션을 제공한다.
특징은 다음과 같다.
- 사용하기 편리하다.
- 매우 빠르다.
- MediaPipe는 GPU 가속을 통해 빠른 처리 성능을 제공한다.
- 많은 MediaPipe 솔루션은 실시간 애플리케이션에서 사용하기 위해 최적화되어 있다.
- 커스터마이징이 가능하다.
- 개발자는 MediaPipe 그래프를 사용하여 자신의 파이프라인을 쉽게 구성하거나 수정할 수 있다.
- 솔루션 기반이다.
- MediaPipe는 얼굴 인식, 손 추적, 포즈 추정 등과 같은 여러 미리 만들어진 ML 솔루션을 제공한다. 이를 통해 개발자들은 복잡한 ML 파이프라인을 간단히 구축하고 사용할 수 있다.
- MediaPipe는 오픈 소스 프레임워크로, 개발자들은 코드를 자유롭게 사용, 수정 및 확장할 수 있다.
아래의 사이트로 가면 여러 데모 코드를 참고할 수 있다.
https://developers.google.com/mediapipe
MediaPipe | Google for Developers
An open source, cross-platform, customizable ML solution for live and streaming media.
developers.google.com
모듈 import
import cv2
import mediapipe as mp
import numpy as np
mp_drawing = mp.solutions.drawing_utils
mp_pose = mp.solutions.poseas는 as뒤에 쓴 단축어로 모듈을 호출하겠다는 뜻이다.
mediapipe, cv2, numpy를 가져와 준다.
mediapipe를 사용하여 두개의 객채를 생성해 준다.
- mp_drawing : 실제로 포즈를 시각화할 때 유틸리티를 사용한다.
- mp_pose: 실제로 포즈 추정 모델을 가져오는 것으로, 얼굴, 손 등 다양한 모습들을 가져온다.
화면에 비디오 띄우기
# 비디오 피드
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
cv2.imshow('Mediapipe Feed', frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()- cap = cv2.VideoCapture(0): 비디오 연결하는 코드. 컴퓨터와 연결된 webcam일 수도 있고, usb현미경일 수도 있고, 특정 컴퓨터에 연결된 다른 종류의 카메라일 수도 있다.
- 여기서 숫자 0대신에 비디오 경로를 넣으면 해당 비디오가 실행된다.
- while cap.isOpened(): 비디오가 실행되는 동안(캡이 열려있는 동안) 계속 실행된다.
- cv2.imshow: 이미지를 직접 화면에 보여주는 부분
- if cv2.waitKey(10) & 0xFF == ord('q'):
break- 10이나 q를 누르면 화면을 빠져나온다.(종료한다)
이 코드를 기반으로 코드를 구축해보자.
mp_pose.POSE_CONNECTIONS이 코드를 출력하면
frozenset({(0, 1),
(0, 4),
(1, 2),
(2, 3),
(3, 7),
(4, 5),
(5, 6),
(6, 8),
(9, 10),
(11, 12),
(11, 13),
(11, 23),
(12, 14),
(12, 24),
(13, 15),
(14, 16),
(15, 17),
(15, 19),
(15, 21),
(16, 18),
(16, 20),
(16, 22),
(17, 19),
(18, 20),
(23, 24),
(23, 25),
(24, 26),
(25, 27),
(26, 28),
(27, 29),
(27, 31),
(28, 30),
(28, 32),
(29, 31),
(30, 32)})이렇게 숫자가 나오는데, 각 숫자는 몸의 어떤 부위에 연결되더 있는지를 확인해 볼 수 있다.
예를 들어 코(0)는 눈(1, 4) 와 연결된것을 확인해볼 수 있다.

출처: https://developers.google.com/mediapipe/solutions/vision/pose_landmarker#pose_landmarker_model
Pose landmark detection guide | MediaPipe | Google for Developers
The MediaPipe Pose Landmarker task lets you detect landmarks of human bodies in an image or video. You can use this task to identify key body locations, analyze posture, and categorize movements. This task uses machine learning (ML) models that work with s
developers.google.com
모션 탐지하기
cap = cv2.VideoCapture(0)
## 미디어파이프 인스턴스 설정(신뢰도는 0.5, 연속 프레임 신뢰도 0.5)
with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
while cap.isOpened():
ret, frame = cap.read()
# 이미지 다시 칠하기: 미디어 파이프에 전달하기 위해 BGR -> RGB로 변경
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image.flags.writeable = False # 쓰기 가능상태를 false로 지정
# 감지하기
results = pose.process(image)
# 이미지 도트 쓰기 기능 True로 하고 RGB -> BGR로 색 변
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 렌더링한 이미지를 감지
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(245,117,66), thickness=2, circle_radius=2), # 점 색상 변경
mp_drawing.DrawingSpec(color=(245,66,230), thickness=2, circle_radius=2) # 라인 색상 변경
)
cv2.imshow('Mediapipe Feed', image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()- with mp_pose.Pose(...) as pose:
- MediaPipe의 Pose 모듈을 사용하기 위한 컨텍스트 매니저로, pose 객체를 통해 포즈 추정이 이루어진다.
- min_detection_confidence:
- 이 값은 포즈가 처음 감지될 때 필요한 최소 신뢰도(confidence)를 설정한다.
- 값이 0.5인 경우, MediaPipe의 포즈 감지 알고리즘이 50% 이상의 신뢰도로 포즈를 감지했을 때만 해당 포즈를 유효하게 간주한다.
- 이 값을 너무 낮게 설정하면 잘못된 감지가 증가할 수 있으며, 너무 높게 설정하면 유효한 포즈를 놓칠 수 있다.
- min_tracking_confidence:
- 이 값은 포즈가 한 번 감지된 후, 연속 프레임에서 해당 포즈를 추적할 때 필요한 최소 신뢰도를 설정한다.
- 예를 들어, 값이 0.5인 경우, MediaPipe의 포즈 추적 알고리즘이 50% 이상의 신뢰도로 포즈를 추적했을 때만 해당 포즈를 유효하게 간주한다.
- min_detection_confidence와 마찬가지로, 이 값을 너무 낮게 설정하면 잘못된 추적이 발생할 수 있고, 너무 높게 설정하면 포즈 추적을 놓칠 수 있다.
위 코드를 실행시켜 보면 미디어파이프는 꽤 정확하고 빠르게 몸 부분을 감지하는 것을 볼 수 있다.
관절 결정하기
위의 사진을 다시 참고하자면,
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index각 숫자는 관절의 위치를 나타낸다.
랜드마크 코드를 추가한 코드이다.
아래 코드를 실행하면 랜드마크가 실행된다.
cap = cv2.VideoCapture(0)
## 미디어파이프 인스턴스 설정(신뢰도는 0.5, 연속 프레임 신뢰도 0.5)
with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
while cap.isOpened():
ret, frame = cap.read()
# 이미지 다시 칠하기: 미디어 파이프에 전달하기 위해 BGR -> RGB로 변경
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image.flags.writeable = False
# 감지하기
results = pose.process(image)
# 이미지 도트 쓰기 기능 True로 하고 RGB -> BGR로 색 변
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 랜드마크 추출
try:
landmarks = results.pose_landmarks.landmark
except:
pass
# 렌더링한 이미지를 감지
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(245,117,66), thickness=2, circle_radius=2),
mp_drawing.DrawingSpec(color=(245,66,230), thickness=2, circle_radius=2)
)
cv2.imshow('Mediapipe Feed', image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
이를 프린트로 찍어보면 위와 같이 실행되는데, 이는 프레임 속 관절의 위치이다.
여기서 우리는 일부 관절을 추출 볼 것이다.
len(landmarks)
이 수를 추출하면 33개가 나온다.
for lndmrk in mp_pose.PoseLandmark:
print(lndmrk)각 랜드마크가 참조하는 순서는 다음과 같다. 0번은 코, 1번은 왼쪾 안쪽 눈, 2번은 왼쪽 눈... 이렇게 순서대로 33개가 존재한다.
PoseLandmark.NOSE
PoseLandmark.LEFT_EYE_INNER
PoseLandmark.LEFT_EYE
PoseLandmark.LEFT_EYE_OUTER
PoseLandmark.RIGHT_EYE_INNER
PoseLandmark.RIGHT_EYE
PoseLandmark.RIGHT_EYE_OUTER
PoseLandmark.LEFT_EAR
PoseLandmark.RIGHT_EAR
PoseLandmark.MOUTH_LEFT
PoseLandmark.MOUTH_RIGHT
PoseLandmark.LEFT_SHOULDER
PoseLandmark.RIGHT_SHOULDER
PoseLandmark.LEFT_ELBOW
PoseLandmark.RIGHT_ELBOW
PoseLandmark.LEFT_WRIST
PoseLandmark.RIGHT_WRIST
PoseLandmark.LEFT_PINKY
PoseLandmark.RIGHT_PINKY
PoseLandmark.LEFT_INDEX
PoseLandmark.RIGHT_INDEX
PoseLandmark.LEFT_THUMB
PoseLandmark.RIGHT_THUMB
PoseLandmark.LEFT_HIP
PoseLandmark.RIGHT_HIP
PoseLandmark.LEFT_KNEE
PoseLandmark.RIGHT_KNEE
PoseLandmark.LEFT_ANKLE
PoseLandmark.RIGHT_ANKLE
PoseLandmark.LEFT_HEEL
PoseLandmark.RIGHT_HEEL
PoseLandmark.LEFT_FOOT_INDEX
PoseLandmark.RIGHT_FOOT_INDEX
각 부분의 랜드마크를 숫자로 추출해 보자.
위 코드에서 landmarks: 신체 부위의 3D 좌표와 관련된 정보를 포함
- 왼쪽 어깨의 가시성 점수
landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].visibility0.9992413520812988-> visibility 값이 1에 가까울수록 해당 랜드마크는 확실히 보이고 있음을 의미한다.
- 왼쪽 어깨의 랜드마크 정보를 가져오기
landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value]x: 0.7438367009162903
y: 0.8448633551597595
z: -0.49983009696006775
visibility: 0.9992413520812988이 정보는 보는 좌표(x, y, z)와 가시성 점수(visibility)를 포함하고 있다.
- 어깨의 인덱스 번호 가져오기
mp_pose.PoseLandmark.LEFT_SHOULDER.value11위 그림에서 본 것처럼 인덱스 번호가 출력된다.
관절의 각도 계산하기
손목과 팔꿈치, 어깨가 이루는 각을 계산해 보자.
아래는 각도를 반환하는 함수이다.
def calculate_angle(a,b,c):
# 각 값을 받아 넘파이 배열로 변형
a = np.array(a) # 첫번째
b = np.array(b) # 두번째
c = np.array(c) # 세번째
# 라디안을 계산하고 실제 각도로 변경한다.
radians = np.arctan2(c[1]-b[1], c[0]-b[0]) - np.arctan2(a[1]-b[1], a[0]-b[0])
angle = np.abs(radians*180.0/np.pi)
# 180도가 넘으면 360에서 뺀 값을 계산한다.
if angle >180.0:
angle = 360-angle
# 각도를 리턴한다.
return angle팔을 구부렸다 폈다 하는 각도가 180도가 넘지 않으므로, 반환된 각도는 360도에서 빼서 반환해 준다.
어깨, 팔꿈치, 팔목 값들을 출력해 보자.
shoulder = [landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].x,landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].y]
elbow = [landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value].x,landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value].y]
wrist = [landmarks[mp_pose.PoseLandmark.LEFT_WRIST.value].x,landmarks[mp_pose.PoseLandmark.LEFT_WRIST.value].y]shoulder, elbow, wrist([0.7438367009162903, 0.8448633551597595],
[0.9458853602409363, 1.3214348554611206],
[0.9430956840515137, 1.7426143884658813])
위 함수에 이 값들을 넣고 출력하면
calculate_angle(shoulder, elbow, wrist)156.64536266620797156도정도의 값이 나온다.
값들을 계산하여 팔을 굽힐때마다 1씩 올라가게 만드는 코드를 생성한다.
전체 코드는 다음과 같다.
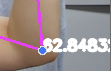
cap = cv2.VideoCapture(0)
## Setup mediapipe instance
with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
while cap.isOpened():
ret, frame = cap.read()
# Recolor image to RGB
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image.flags.writeable = False
# Make detection
results = pose.process(image)
# Recolor back to BGR
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# Extract landmarks
try:
landmarks = results.pose_landmarks.landmark
# Get coordinates
shoulder = [landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].x,landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].y]
elbow = [landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value].x,landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value].y]
wrist = [landmarks[mp_pose.PoseLandmark.LEFT_WRIST.value].x,landmarks[mp_pose.PoseLandmark.LEFT_WRIST.value].y]
# Calculate angle
angle = calculate_angle(shoulder, elbow, wrist)
# Visualize angle
cv2.putText(image, str(angle),
tuple(np.multiply(elbow, [640, 480]).astype(int)),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2, cv2.LINE_AA
)
except:
pass
# Render detections
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(245,117,66), thickness=2, circle_radius=2),
mp_drawing.DrawingSpec(color=(245,66,230), thickness=2, circle_radius=2)
)
cv2.imshow('Mediapipe Feed', image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()위 코드를 실행하면 팔을 굽혔다 폈다 할 때마다 1씩 올라가는 모습을 확인할 수 있다.
코드 설명
# Get coordinates
shoulder = [landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].x,landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].y]
elbow = [landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value].x,landmarks[mp_pose.PoseLandmark.LEFT_ELBOW.value].y]
wrist = [landmarks[mp_pose.PoseLandmark.LEFT_WRIST.value].x,landmarks[mp_pose.PoseLandmark.LEFT_WRIST.value].y]이 부분에서 각 값들을 읽어온다. x, y, z값 이렇게 총 3개의 값이 있는데, 각 값에서 2차원의 값만 얻어 각도를 계산하고 싶으므로 x, y값만 가져온다.
# Calculate angle
angle = calculate_angle(shoulder, elbow, wrist)각 값을 계산하여 각도를 반환받는다.
# Visualize angle
cv2.putText(image, str(angle),
tuple(np.multiply(elbow, [640, 480]).astype(int)),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2, cv2.LINE_AA
)화면에 각도를 표시한다. 이 값은 팔꿈치 위치에 표시된다.
cv.putText() 메서드
cv2.putText() 함수는 OpenCV에서 이미지 위에 텍스트를 그리기 위해 사용하는 함수이다.
- image: 텍스트를 그릴 대상 이미지입니다.
- text: 그릴 텍스트 문자열입니다.
- org: 이미지에서 텍스트 문자열의 왼쪽 하단 모서리 좌표입니다.
- 이 좌표는 두 값의 튜플로 표현된다. - 즉, (X 좌표 값, Y 좌표 값)입니다.
- font: 사용할 글꼴의 유형을 나타냅니다. 사용 가능한 글꼴 유형에는 FONT_HERSHEY_SIMPLEX, FONT_HERSHEY_PLAIN 등이 있습니다.
- fontScale: 글꼴 특정 기본 크기에 곱해지는 글꼴 스케일 인자입니다.
- color: 그릴 텍스트 문자열의 색상입니다. BGR에 대해 색상은 튜플로 전달됩니다. 예: 파란색의 경우 (255, 0, 0).
- thickness: 선의 두께를 픽셀로 나타냅니다.
- lineType: 이것은 선택적 파라미터입니다. 사용할 선의 유형을 지정합니다.
- bottomLeftOrigin: 선택적 파라미터입니다. 이 값이 True일 경우, 이미지 데이터의 원점은 왼쪽 하단 모서리에 있습니다. 그렇지 않으면, 왼쪽 상단 모서리에 있습니다.
# Curl counter logic
if angle > 160:
stage = "down"
if angle < 30 and stage =='down':
stage="up"
counter +=1
print(counter)만약 각도가 160도가 넘으면, down이라고 저장한다.
각도가 30도보다 적거나 down 이라고 stage변수에 저장되어 있으면 counter를 1씩 늘린다.
# Setup status box
cv2.rectangle(image, (0,0), (225,73), (245,117,16), -1)cv2.rectangle 파라미터
img: 직사각형이 그려질 이미지입니다.
pt1: 직사각형의 왼쪽 상단 모서리 좌표입니다. (x, y) 형태의 튜플로 주어집니다.
pt2: 직사각형의 오른쪽 하단 모서리 좌표입니다. (x, y) 형태의 튜플로 주어집니다.
color: 직사각형의 색상입니다. BGR 포맷으로 튜플 (Blue, Green, Red) 형태로 주어집니다. 예를 들어, 파란색은 (255, 0, 0)으로 표현됩니다.
thickness (선택적): 직사각형 선의 두께를 픽셀 단위로 지정합니다. -1을 지정하면 직사각형 내부를 채웁니다.
lineType (선택적): 선 유형을 지정합니다. 예를 들어, cv2.LINE_8, cv2.LINE_AA 등의 값이 있습니다. cv2.LINE_AA는 안티 앨리어싱 라인을 나타냅니다.
shift (선택적): 좌표 값의 소수점 자릿수입니다. 기본값은 0입니다.
정리 내용이 부족한 것 같아 수정 예정
'개발공부 > 머신러닝,딥러닝' 카테고리의 다른 글
| CNN keras 모듈 사용하여 졸음 방지 모델 생성하기 (0) | 2023.09.05 |
|---|---|
| [Python] 로지스틱 회귀(LogisticRegression) 이용하여 붓꽃 데이터 분석 (0) | 2023.08.18 |
| [Python] 선형 회귀(Linear Regression) 이용하여 보스턴 하우스 집값 예측하기 (0) | 2023.08.17 |
| [Python] sklearn 모듈 KNeighborsClassifier 알고리즘으로 도미, 빙어 구분하기 (0) | 2023.08.16 |
